
烂尾工程: Java实现的汇编语言编译器
在半年前的中文编程的尝试历程小记中简单介绍了这一项目. 由于短期内估计不会继续进行, 而且这个项目好像是至今个人在中文命名实践中的代码量最大的一个项目, 谨在此作一小结. 最新的源码库在program-in-chinese/assembler-in-chinese-experiment.
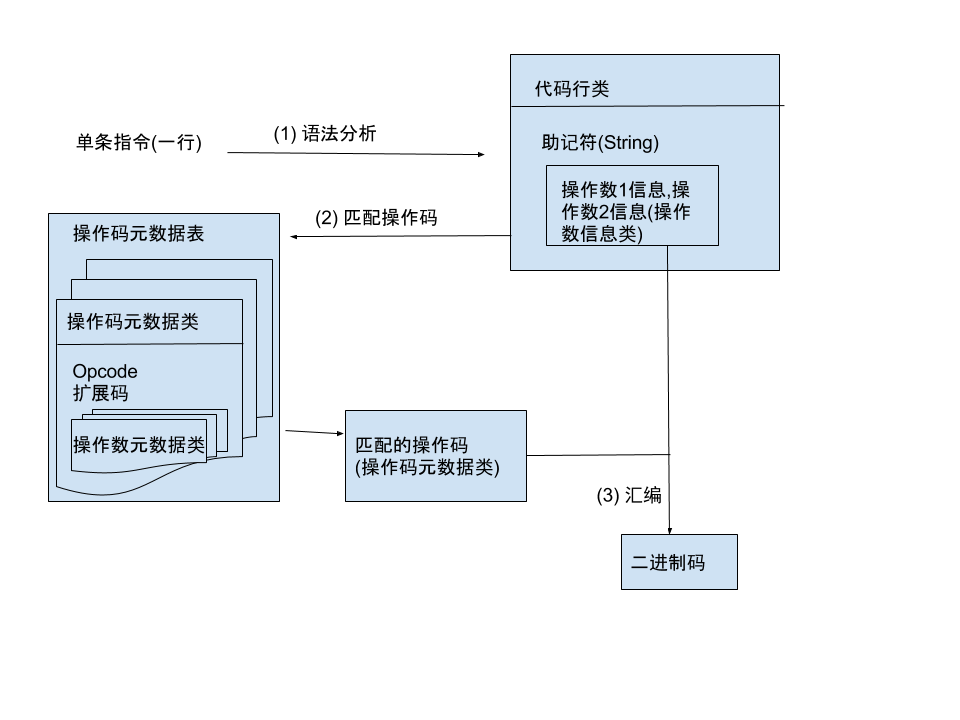
大致设计草图
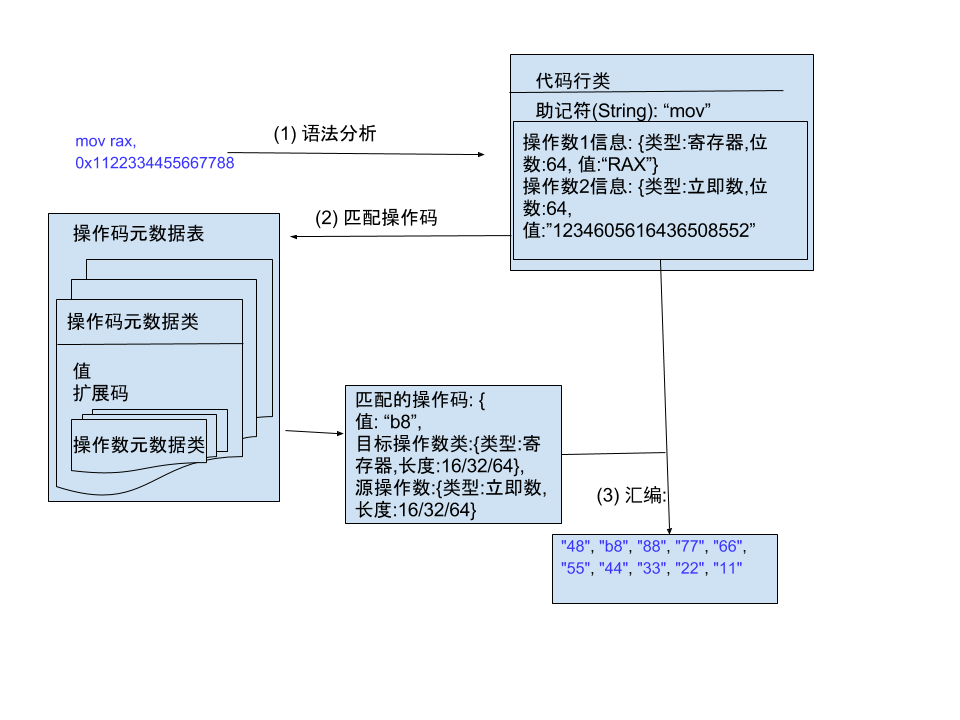
以’mov rax 0x1122334455667788’指令示例如下:
当前进度
- 仅支持两个操作数的部分指令, 第二个操作数仅支持立即数
- 第一个操作数可以是寄存器,或者简单的内存寻址,如[0]
- 支持强制类型,如add ax,strict word 5
- 生成空可执行文件(PE), 尚未填入生成的二进制码
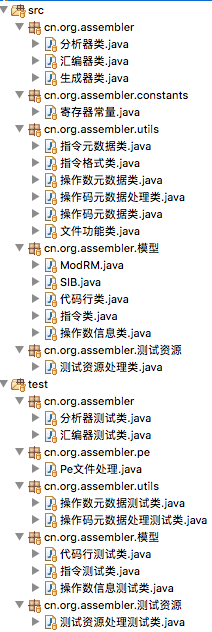
源码结构
下面是所有文件, 希望是一目了然? “分析器类”从单行汇编指令字符串分析生成”代码行类”, “汇编器类”从”代码行类”生成二进制码. 其他主要是业务数据描述(“模型”包)和功用(utils).
假如要重新继续这一项目, 下面是一些想法:
- 考虑使用Antlr4, 用类似antlr/grammars-v4的语法文件辅助生成分析器, 省去手动编写分析器
- 最好有汇编和x64指令背景的开发者