
Xtext试用: 快速实现简单领域专用语言(DSL)
环境搭建
使用的Eclipse版本: Oxygen.1a Release (4.7.1a) Build id: 20171005-1200, 通过添加Xtext - Download上列出的Releases update site安装xtext IDE和xtext SDK. 之后打开Eclipse, 打开任何文件就报错:
An error has occurred. See error log for more details.
loader constraint violation: loader (instance of org/eclipse/osgi/internal/loader/EquinoxClassLoader) previously initiated loading for a different type with name "org/aspectj/runtime/internal/AroundClosure"
为避免现有插件和它的冲突, 新安装了更新版Eclipse: Version: Oxygen.2 Release (4.7.2) Build id: 20171218-0600
官方教程原代码试用
首先, 参考官方教程: 15 Minutes Tutorial
教程按部就班, 基本没有问题. 唯一碰到的坑是最后将一个dsl文件拆分成多个时, 发现需要将项目转换为xtext project才能支持(Xtext cross-reference across all files in project)
接着的第二个教程: 15 Minutes Tutorial - Extended, 问题多了些.
“Unit Testing the Language”部分中的文件在.tests项目的src/中, 只有个小坑. 下面的parser就是原来模板文件中的parseHelper
val model = parser.parse(
"entity MyEntity {
parent: MyEntity
}")
“Creating Custom Validation Rules”部分中的checkFeatureNameIsUnique 初一运行后, 在同一Entity内两个同名Feature没有报错, ==改为.equals()也无用. 细一看之后, 才发觉它是检查父子Entity内是否有同名Feature. 比如在Comment中添加’author’的Feature, 如期报错.
这里感觉到xtend语言的特别, 发现它本身也是个JVM语言: Xtend - Modernized Java, 不过貌似远没有Kotlin的流行度(后发现本站的代码块语言选项中竟然有xtend).
框架对中文的支持
首先, 尝试生成中文关键词的DSL. 默认ID只包含英文,数字,下划线, 因此自定义IDENTIFIER,
grammar org.example.domainmodel.Domainmodel with org.eclipse.xtext.common.Terminals
generate domainmodel "http://www.example.org/domainmodel/Domainmodel"
import "http://www.eclipse.org/emf/2002/Ecore" as ecore
Domainmodel:
(elements+=AbstractElement)*;
PackageDeclaration:
'包' name=QualifiedName '{'
(elements+=AbstractElement)*
'}';
AbstractElement:
PackageDeclaration | Type | Import;
QualifiedName:
IDENTIFIER ('.' IDENTIFIER)*;
Import:
'导入' importedNamespace=QualifiedNameWithWildcard;
QualifiedNameWithWildcard:
QualifiedName '.*'?;
Type:
DataType | Entity;
DataType:
'数据类型' name=IDENTIFIER;
Entity:
'类' name=IDENTIFIER ('扩展' superType=[Entity|QualifiedName])? '{'
(features+=Feature)*
'}';
Feature:
(many?='复数')? name=IDENTIFIER ':' type=[Type|QualifiedName];
terminal IDENTIFIER: '^'?('\u4E00'..'\u9FA5'|'\uF900'..'\uFA2D'|'a'..'z'|'A'..'Z'|'_') ('a'..'z'|'A'..'Z'|'_'|'0'..'9'|'\u4E00'..'\u9FA5'|'\uF900'..'\uFA2D')*;
一个小问题. 由于IDENTIFIER开头支持下划线, Generate Xtext Artifacts时会警告如下, 但似乎不影响语言生成, 下划线开头支持也正确:
error(208): ../org.example.mydsl/src-gen/org/example/domainmodel/parser/antlr/internal/InternalDomainmodel.g:571:1: The following token definitions can never be matched because prior tokens match the same input: RULE_ID
error(208): ../org.example.mydsl.ide/src-gen/org/example/domainmodel/ide/contentassist/antlr/internal/InternalDomainmodel.g:1258:1: The following token definitions can never be matched because prior tokens match the same input: RULE_ID
另一个问题是, 语法规则中的规则名称不能用中文命名(比如Feature改为’性状’, PackageDeclaration改为’包声明’等), 否则在Generate Xtext Artifacts生成报错并中断:
java.lang.RuntimeException: Problems running workflow org.xtext.example.mydsl.GenerateMyDsl: Problem parsing 'file:/Users/xuanwu/work/workspace-xtext/org.example.mydsl/../org.example.mydsl/src/org/xtext/example/mydsl/MyDsl.xtext':
XtextSyntaxDiagnostic: null:10 extraneous input '包' expecting ':'
经测试, DSL语言高亮在Eclipse中显示正确:
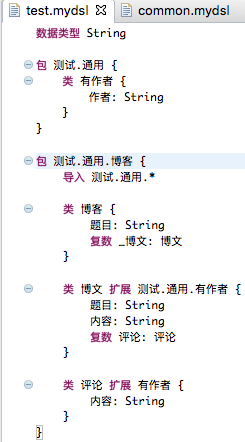
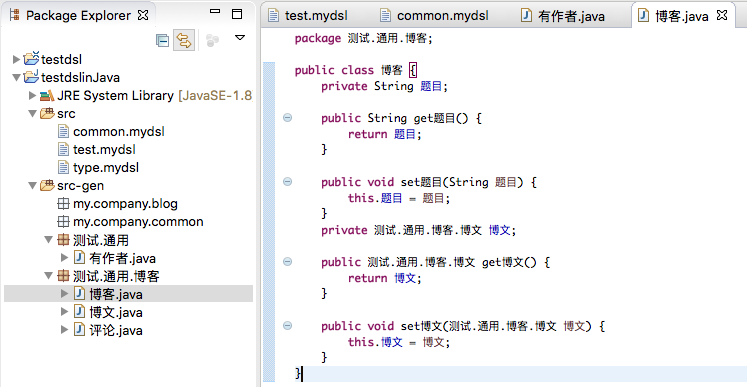
并且生成Java Beans正确(需要将数据类型名称由上面的”字符串”改为”String”):
另外, 经测试xtend也支持中文命名(节选DomainmodelValidator如下), 但由于xtext语法文件不支持中文标识符, 影响有限:
@Check
def void 检验子类无父类重名性状(Feature f) {
var 父类 = (f.eContainer as Entity).superType
while (父类 !== null) {
for (其他 : 父类.features) {
if (f.name == 其他.name) {
error("子类性状不能与父类中性状重名",
DomainmodelPackage.Literals.FEATURE__NAME)
return
}
}
父类 = 父类.getSuperType();
}
}
演示如下:

以上xtext项目源码在program-in-chinese/xtext_tutorial_15_min_zh
测试DSL项目源码: program-in-chinese/xtext_tutorial_15_min_zh
初步小结
长处:
- 工具本身和基本文档质量尚可, 基本功能(源码分析, 新代码生成), 上手还算快. 应该至少可以适用于简单DSL实验.
- 语法规则描述接近EBNF. 好像功能更多(equivalent BNF-grammar of grammar written in XText)
短处:
- 最大问题是语法规则中标识符不能中文命名, 直接导致相关的代码生成器(generator)和验证器使用的多数API只能是英文(如上面的.name, .features).
- Eclipse版本或者插件冲突问题需要规避
- 需要学习xtend语言, 虽然可能很像Java
未尝试: 可否定制自动补全功能, 语法报错信息(比如下面)

另外希望有机会继续尝试下一篇教程: Five simple steps to your JVM language